The most typical psychological term for functions carried out by the prefrontal cortex area is executive function. Executive function relates to abilities to differentiate among conflicting thoughts, determine good and bad, better and best, same and different, future consequences of current activities, working toward a defined goal, prediction of outcomes, expectation based on actions, and social "control" (the ability to suppress urges that, if not suppressed, could lead to socially unacceptable outcomes). From Wikipedia
What is Welcomer?
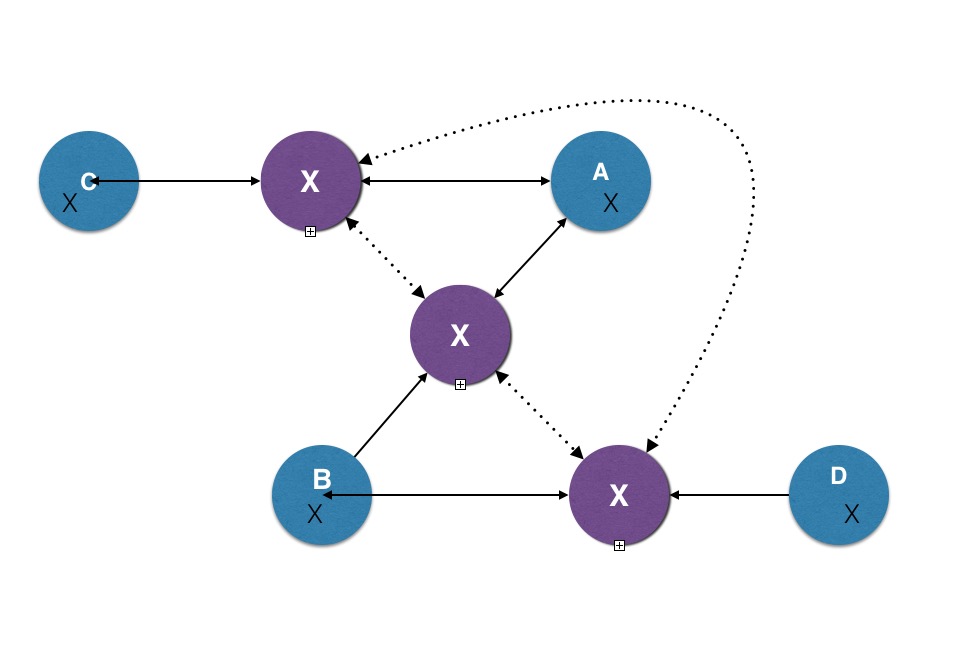
Welcomer is Open Source Software installed with data silos. The installation of the software links the Welcomer code and a copy of data from the silo into the Welcomer network. This permits permanent links to be established to any other Welcomer installation. It links data elements for an entity in one data silo to the "same data element" for the same entity in other silos. This means executive applications have access to data about the same entity from many different applications. It can provide "big data" summaries from other similar entities to help executive applications. Executive applications perform similar functions to the prefrontal cortex but for any electronic entity.
Examples of personal executive applications acting like a prefrontal cortex
Executive applications can perform the same executive functions as a prefrontal cortex for the electronic memories of any object. The memories are electronic data stored in data silos that result from existing functional applications, like paying a bill, searching using search terms, or recognising a face in a photo. The functional applications provide the raw material for memories. Welcomer links memories across applications across organisations. This allows Welcomer to differentiate among conflicting data across applications. It enables applications to reflect and simulate what will happen with other applications if certain actions are taken and for entities to compare themselves to others using the same application.
A simple example is when you change your name as a result of deed poll or marriage ceremony an executive application can alert you that your name must be changed in other places and assist you do it.
An executive loan application can help you obtain a loan. You can hypothesise a loan amount and the application can check if the loan will cause conflicts with existing loan agreements. You can be given a strategy to achieve a loan. This might take various forms of finding another way to achieve the purpose of the loan, reducing expenses, increase income, or restructure existing agreements.
You can be alerted when someone tries to steal your identity. A transaction may be delayed or stopped or observed when someone, purporting to be you, uses a new device to try to conduct a transaction 1,000 miles from where you have just logged in to another application.
Data about any entity can be collated. We often think of applications as being about people but any entity can be reasoned about by considering data from multiple sources and applications. There are records about a house scattered over many data silos. The house might be alerted to some maintenance that needs to be carried out. The house can then alert the person responsible and let them know options. The sales data about other houses is available to the house owner to help them make buy or sell decisions.
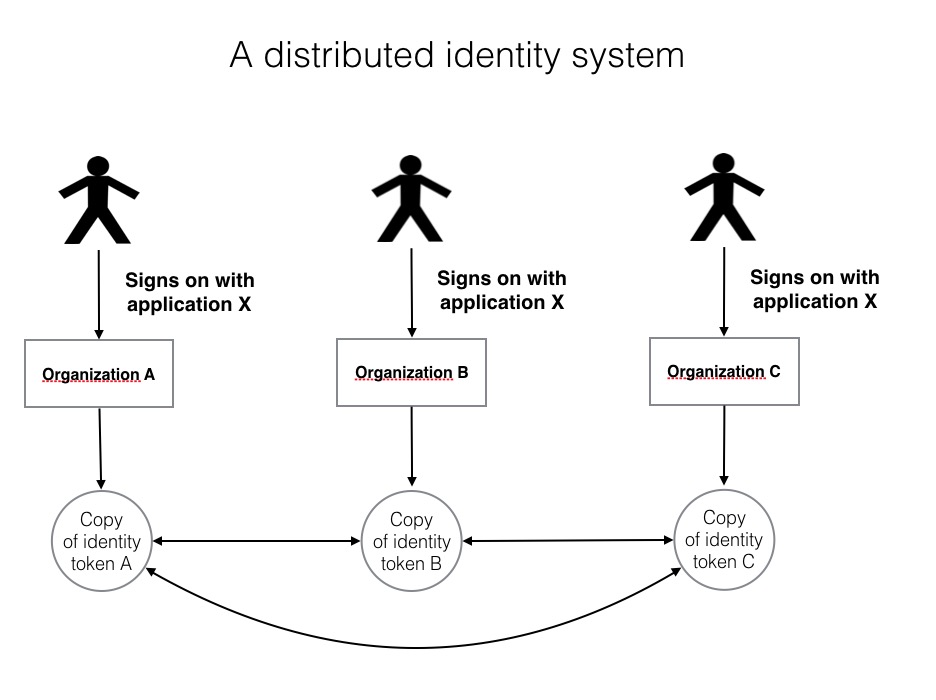
Organisations are entities and Welcomer assists organisations with their existing executive applications. A common executive application is getting a "single view" of a customer or member. Organisations have many diverse operational applications that contain personal data. If Welcomer is used to give each individual a view of their own data then an organisation also gets a single view of that customer's data across all its applications. The advantage to an organisation is by complying with privacy regulations around personal data the organisation achieves a previously difficult corporate goal.
Many existing executive applications that organisations have can be made available to customers and members to enhance the user experience. With payments, organisations give customers many ways to pay for goods and services. The inverse is for customers and members to have many ways that they can pay. A Welcomer executive application can match the payment methods for the organisation with the methods available to the customer to the mutual benefit and convenience of both parties.
How it works
Data silos are regular data bases that are created with regular applications. The silos are discrete and contained. The elements to be exposed from the data silo are defined by the owner of the silo deciding what data items representing what concept or object can be linked to other data silos. A silo might define a name as a string of characters that can be broken into parts. It might say that if there is one part it is a given name, if there are two parts it is given name followed by surname. This information is exposed to other silos and the other silos can decide to allow names they have in their data silo to be linked to an existing data silo. When name is actually linked by the person between two silos this automatically links to all other linked silos for the person.
Linked data silos transmit data across the links using messages. Message passing is essential because this means connections are via data content not via indexes or location. The receiving data silo decides independently and secretly what it will do with the received data. These rules are specified by the owner of the data silo. The form of the rules are built into the Welcomer software and they specify what happens when the silo receives a message relating to the data elements in the silo. Requests for data or to change data can be ignored or acted upon independently by each data silo.
A rule might be that a request to return data will only be allowed if the person has been authenticated with two or more factors. Another rule could be that the application requesting access is in on an approved list and is from an approved organisation.
Once a link is established then it is remembered by its content. That is, when the Welcomer software receives a message it checks to see if the content it receives can be decoded. If it can it decodes it. If it can't it passes the message on to another linked data silo. The total linked silos for any data item is normally small.
Control of access is held within the data silos and is distributed. The sender of a message can also impose rules on access that can be enforced through the Welcomer software. For example, a sender may require the receiver to have agreed to keep the data it receives to be used for defined purposes and to only transmit it to other parties via the Welcomer software.
In summary Welcomer is software that makes permanent connections across data silos and allows applications to access data securely and rapidly no matter where it is held.
Relative advantage of Welcomer
Applications that perform executive functions abound. An advantage of the Welcomer approach is that it decouples existing operational applications from executive applications and provides a standard approach to the collation of data. Welcomer is introduced into an organisation without the need to change existing applications and processes. New applications can be introduced with the ability to get data from existing applications. Operational applications can continue to be developed and deployed and to concentrate on the task required. That is, like the prefrontal cortex we separate executive functions from operational functions.
Other strategies to achieve the same goals of executive applications are:
- centralise and use a common suite of applications from a single vendor or from vendors that use the same software platform.
- use different vendors and to use standard interfaces between applications.
- provide translation gateways between systems
Advantages of the Welcomer approach is that it is leaves existing systems intact, it is scalable, simpler and easier to change. Welcomer does not replace other approaches. Rather it provides another dimension to enhance the capabilities of existing and future applications.
BlockChain is promoted as offering a solution to the connection problem across different data bases by providing a distributed common index or distributed ledger. Welcomer's underlying structure of providing permanent links to "the same" data elements is a very flexible, simple distributed ledger.
Welcomer can be built on top of systems like the Inter Planetary File System (IPFS) as they both access data by content.
Outcomes of Connecting Data by content
The underlying communication structure along with the ability to specify enforceable rules as executive functions means that existing applications are more effective in the following ways.
- data access permissions are enforceable.
- distributed ledger systems are easy to deploy and operate.
- data can be safely replicated and stored in multiple places to reduce transmission costs.
- backup of data can be achieved by storing data in multiple places.
- data does not get "lost" because a hyperlink is broken or no longer active.
- secure private communications channels are easily deployed.
- applications can provide highly secure authentication processes for transactions
- individuals have access to personal data in data silos held by organisations
Distributed ledger systems have many applications. Amongst them are
- control land titles transfers
- allow secret anonymous voting
- allow collection of verified unidentified data
- individuals and organisations issuing their own credit